CUDA(Compute Unified Device Architecture;統一計算架構)技術探討
作者/孫崧閔
前言
CUDA(Compute Unified Device Architecture;統一計算架構[1])是由NVIDIA所推出的一種整合技術,是該公司對於GPGPU(General-Purpose computing on Graphics Processing Units)的正式名稱,透過這個技術,使用者可利用NVIDIA的GeForce 8以後的GPU和較新的Quadro GPU進行計算。它使用 C 語言為基礎,可以直接以大多數人熟悉的C語言,寫出在顯示晶片上執行的程式,而不需要去學習特定的顯示晶片的指令或是特殊的結構,使用者只要準備好附檔名為.cu的CUDA程式碼檔案,然後利用CUDA的編譯器來編譯即可。
CUDA架構圖
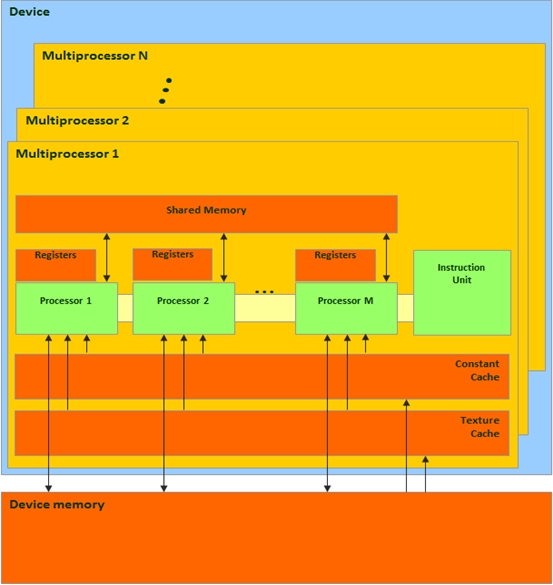
《圖一》
主機(host):插顯示卡的那台電腦。
裝置(device):插在電腦主機板上的顯示卡。
核心(kernel):在顯示卡上執行的程式碼區段。
因為GPGPU屬於外部裝置(device),其機器指令有別於傳統CPU,所以程式核心(kernel)必須經過特殊編譯後,在執行時期和所需的資料由host送到device中,並在執行完成後,將結果資料傳回主機,流程如下圖二。
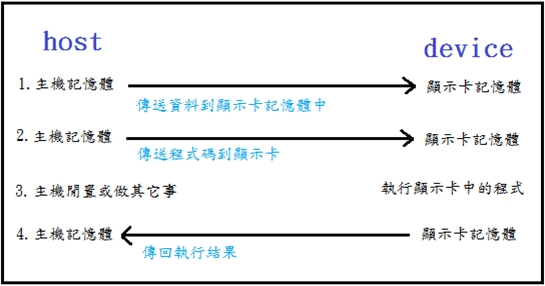
《圖二》
實際上,CUDA提供了很多API簡化這些流程,包括記憶體在兩者間的搬移,顯示卡記憶體的配置與釋放,kernel設定、啟動與同步等,所以上面的每一個步驟其實就是去叫用CUDA函式而已。
CUDA的平行化程式設計模型
網格(Grid):含數個區塊的執行單元。
區塊(Block):含數個執行緒的執行單元。
執行緒(Thread):最小的處理單元。
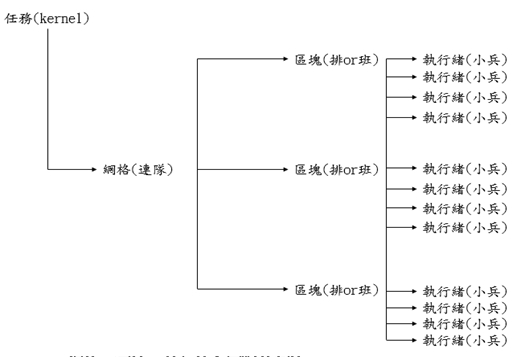
《圖三》kernel、網格、區塊、執行緒和軍隊的類比
我們可以透過內建變數來辨識每個執行緒,讓每個小兵弄清楚要執行那一部份的任務,基本的內建變數如下,它們只可以使用在 kernel 的程式碼中:
uint3 gridDim:網格大小(網格包含的區塊數目)。
uint3 blockIdx:區塊索引(區塊的ID)。
uint3 blockDim:區塊大小(每塊區塊包含的執行緒數目)。
uint3 threadIdx:執行緒索引(執行緒的ID)。
其中uint3為3D的正整數型態
struct uint3{
unsigned int x,y,z;
};
可以運用它來實做更高層次的平行運算結構,不過現階段,先不要管這種複雜的結構,把它當成單一正整數即可,也就是 y 和 z 都當成是 1,只用 uint3 的 x。
網格和區塊大小
一、每一個 block 所能包含的 thread 數目是有限的。不過,執行相同程式的 block,可以組成 grid。
二、不同 block 中的 thread 無法存取同一個共用的記憶體,因此無法直接互通或進行同步。
三、不同 block 中的 thread 能合作的程度是比較低的。
下圖是示意圖:
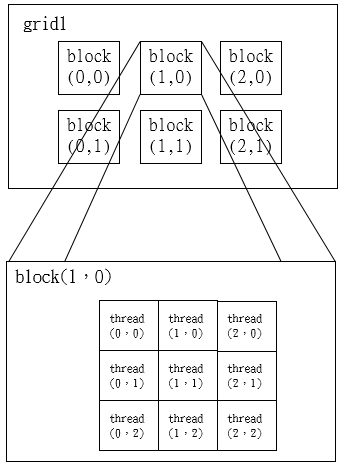
《圖四》
在CUDA中呼叫kernel函式的語法和呼叫一般C函式並沒有太大的差異,只是多了延伸的語法來指定網格和區塊大小而已:
kernel_name<<<gridDim,blockDim>>>(arg1,arg2,…)
kernel_name:核心函式名稱。
gridDim:網格大小。
blockDim:區塊大小。
arg1,arg2,…:函式要傳的引數(和C相同)。
其中gridDim和blockDim可以是固定數字或動態變數,例如:
一、固定數字
ooxx_kernel<<<123,32>>>(result,int1,int2);
二、動態變數
int grid=some_function_g(); //計算網格大小
int block=some_function_b();//計算區塊大小
ooxx_kernel<<<grid,block>>> (result,int1,int2);
區塊和執行緒索引
我們可以用區塊和執行緒索引來定出正在執行的程式位置,以決定該載入什麼樣的資料,而 blockIdx, threadIdx 這兩個變數和 gridDim, blockDim 一樣,在 kernel 中也是內建的唯讀變數,可直接讀取。
例如我們要定義每一個thread的唯一ID,可以用下面這段程式碼:
int id=blockIdx.x*blockDim.x+threadIdx.x;
kernel函式的語法
用CUDA寫kernel函式寫一般C函式也是沒什麼太大的差異,只是多了延伸語法來加入一些特殊功能,並且標明這個函式式kernel而已:
__global__ void kernel_name(type1 arg1,type2 arg2,…){
//函式內容
};
__global__:標明這是kernel的延伸與法。
void:kernel傳回值只能是void。
kernel_name:函式名稱。
type1 arg1,type2 arg2,…:函式引數(和C完全相同)。
函式內容:跟寫C或C++一樣(但不能夠呼叫主機函式)。
Global函式只能在host函式中呼叫,不能在其它global中呼叫。
記憶體種類
CUDA的記憶體種類很繁雜,依照重要順序排列,可分為下六種。
一、暫存器(register):
是所有記憶體中最快的,執行緒中大部份的局部變數都預設使用暫存器,包括陣列(array)也是,但有些情況下,它會被編譯器以較慢的區域記憶體取代,這些情況包括在執行緒中「同時佔用」過多變數,以致於使用的暫存器數目超過編譯器的限制(可使用 --maxrregcount N 選項來限制,預設 N=128 ),或是使用動態變數做為索引存取陣列 (因為此時需要引入陣列的順序結構)。
二、全域記憶體(global memory):
全域記憶體除了使用 __device__ 標籤宣告,另外直接透過 cudaMalloc() 等 API直接配置的記憶體也算,「全域」顧名思義就是所有執行單元都可以對它進行操作,所以凡是放在顯示卡的DRAM中,能夠被所有執行緒操作(包括在不同區塊中的執行緒)皆稱為全域記憶體,它讀取寫入是沒有經過快取的,跟材質快取在硬體上屬於不同的port,必需配合「合併讀取」(coalesced read,也就是半個warp的執行緒同時讀取記憶體中的連續區塊,使記憶體控制器做一次性的合併發出)如此才能增進其效能 (約 5~10x)。
三、共享記憶體(shared memory):
共享記憶體的應用範圍是區塊,只有同一區塊裡的執行緒才可以共用它,使用上要注意它的大小限制,以及存取前後要對執行緒同步化,避免因資料讀寫的先後順序錯誤而導致不可預期的資料錯亂,其效能僅次於暫存器,是最佳化的一個重點項目,另外,我們無法在設計時期對它進行初始化,必需等到核心執行時期才能設定它,而且也無法在主機中對它進行存取,現階段 CUDA 只提供 API 指定其大小。
四、常數記憶體(constant memory):
常數記憶體雖然和材質快取屬於同一個層次,但因其大小受到限制,使快取失誤率非常低,所以在執行時期除了第一次使用需要載入時間外,之後使用和共享記憶體一樣快,它在核心的存取是唯讀的,只能在檔案中使用初始值的方法設定,或是在主機中透過API 進行存取,使用範圍是全域性的。
五、材質快取(texture cache):
因為有快取做為緩衝,所以讀取上不需要做合併,但也因此比直接存取全域記憶體稍微慢一點(數個到數十個週期),但仍比「未合併讀取」全域記憶體快上甚多,所以如果在「合併讀取」很複雜的情況下, 使用材質快取是不錯的選擇,材質快取是唯讀的,在快取的區域性上,除了傳統微處理機的 1D 快取模式外,因繪圖需求的緣故,CUDA 亦提供 2D 和 3D 的材質快取,使用範圍是全域性的。
六、區域記憶體(local memory):
區域記憶體是暫存器不夠用的時候,編譯器自動將資料置換到全域記憶體的產物,有點像作業系統的頁置換(page swap),它對效能的影響是負面的,而且非常地難以捉摸,所以在最佳化程式的時候,時常要用編譯器選項 --ptxas-options=-v來追蹤它,深怕一不小心它就蹦出來,但有時候為了加大區塊中的執行緒數目(blockDim),必需使用編譯器選項 --maxrregcount N 來限制執行緒最大暫存器使用量,沒有它又無法達成這種限制 (同時佔用的變數就這麼多, 一定要置換出去),兩者之間往往必需進行妥協,或使用共享記憶體進行手動置換。
其中最重要的前四種基本的功能如下:
一、暫存器 : 執行緒使用到的一般變數(快速,預設,執行緒內部)。
二、全域記憶體: 同一區塊內的執行緒共用(快速,區塊內交換資料用)。
三、共享記憶體: 存放整個程式共用的常數(快速,有快取,全域共用)。
四、常數記憶體: 顯示卡中的DRAM(很慢,無快取,全域共用)。
記憶體宣告
一、全域記憶體: __device__ //在檔案範圍宣告
二、常數記憶體: __constant__ //在檔案範圍宣告
三、共享記憶體: __shared__ //在函式範圍宣告
結語
採用 CUDA 的GPU 至今已累計售出數百萬顆,軟體開發人員、科學家及研究人員將 CUDA 應用於各種領域中,包括影像及視訊處理、計算生化學、流體力學模擬、電腦斷層 (CT) 影像重建、地震分析、光線追蹤,以及其他更多用途等。
運算已由 CPU 的「中央處理」進化為 CPU 和 GPU 的「協同處理」。為實現此一全新的運算方式, NVIDIA 創造出 CUDA 平行運算架構,現在已運用於熱銷的 Tesla, Quadro及 GeForce GPU 上,顯見對於應用程式開發商而言,這其中已形成龐大的使用者基礎。
CUDA 在科學研究領域中大受青睞,例如 CUDA 能加速 AMBER此一分子動力模擬程式,全球學術界及製藥公司總計約有六萬名以上的研究人員,皆利用此程式加速新藥的研發。 在金融市場上, Numerix 和 CompatibL 已宣布其交易對手風險應用程式支援 CUDA,可將速度提昇達十八倍之多。
CUDA 的普及,可由 Tesla GPU 在 GPU 運算領域中的使用量持續增加看出。《財富雜誌》五百強企業中,總計已建置 700 個 GPU 叢集,包括能源領域中的 Schlumberger 和 Chevron,乃至銀行業的 BNP Paribas 等。
參考資料
1.
NVIDIA官方網站
2.
維基百科
3.
痞客幫